مزایای هوش مصنوعی(AI) برای مراقبت های بهداشتی در سالهای اخیر به طور گسترده مورد بحث قرار گرفته است تا آنجا که می گویند امکانی برای کمک و دستیاری هوش مصنوعی برای پزشکان در آینده وجود دارد.همچنین بحث ها و هم پژوهش های فعلی مبتنی بر هوش مصنوعی نشان می دهد که هوش مصنوعی می تواند به چندین روش در مراقبت های بهداشتی مورد استفاده قرار گیرد:
- هوش مصنوعی می تواند ویژگی ها را از حجم زیادی از داده های مراقبت های بهداشتی بیاموزد و سپس از تفسیر های به دست آمده برای کمک به تمرینات بالینی در طراحی درمان یا ارزیابی ریسک استفاده کند.
- سیستم هوش مصنوعی می تواند اطلاعات مفیدی را از جمعیت زیادی از بیماران استخراج کند تا به استنباط زمان واقعی هشدار خطر سلامتی و پیش بینی نتیجه سلامتی کمک کند.
- هوش مصنوعی می تواند کارهای تکراری، مانند تجزیه و تحلیل آزمایشات، اشعه ایکس، سی تی اسکن یا ورود اطلاعات را انجام دهد.
- سیستم های هوش مصنوعی می توانند به کاهش خطاهای تشخیصی و درمانی کمک کنند که در عمل بالینی انسان اجتناب ناپذیر است.
- هوش مصنوعی می تواند با ارائه اطلاعات پزشکی به روز از ژورنال ها، کتاب های درسی و روش های بالینی، به پزشکان کمک کند تا از مراقبت صحیح بیمار مطلع شوند.
- هوش مصنوعی می تواند سوابق پزشکی را مدیریت کرده و عملکرد هر یک از موسسات و کل سیستم مراقبت های بهداشتی را تجزیه و تحلیل کند.
- هوش مصنوعی می تواند به تولید داروی دقیق و داروهای جدید مبتنی بر پردازش سریع جهش ها و پیوند با بیماری کمک کند.
- هوش مصنوعی می تواند مشاوره دیجیتال و خدمات نظارت بر سلامتی را -در حد “پرستار دیجیتال” یا “ربات های بهداشتی” ارائه دهد.
با وجود کاربردهای متنوع هوش مصنوعی در مطالعات بالینی و خدمات بهداشتی، آنها به دو دسته عمده تقسیم می شوند: تجزیه و تحلیل داده های ساختاری، از جمله تصاویر، ژن ها و نشانگرهای زیستی، و تجزیه و تحلیل داده های غیر ساختاری، مانند یادداشت ها، مجلات پزشکی یا نظرسنجی بیماران برای تکمیل داده های ساختار یافته. رویکرد قبلی توسط الگوریتم های یادگیری ماشین و یادگیری عمیق تقویت می شود، در حالی که روش دوم به روشهای تخصصی پردازش زبان طبیعی بستگی دارد.

الگوریتم های یادگیری ماشین(ML)
الگوریتم های یادگیری ماشین عمدتا ویژگی هایی را از داده ها استخراج می کنند ، مانند “ویژگی های” بیماران و نتایج پزشکی مورد علاقه. برای مدت زمان طولانی، هوش مصنوعی در مراقبت های بهداشتی تحت سلطه رگرسیون لجستیکی، ساده ترین و رایج ترین الگوریتم زمانی که لازم است طبقه بندی شود، بود. استفاده از آن آسان، به پایان رسیدن آن سریع و تفسیر آن ساده بود. با این حال، در سال های گذشته وضعیت تغییر کرده است و SVM و شبکه های عصبی حرف اول را می زنند.

داده ها از طریق جستجو در الگوریتم های یادگیری ماشین در مراقبت های بهداشتی در PubMed تولید می شوند.
برای مدت زمان طولانی، هوش مصنوعی در مراقبت های بهداشتی تحت سلطه رگرسیون لجستیکی، ساده ترین و رایج ترین الگوریتم زمانی که لازم است طبقه بندی شود، بود. و استفاده از آن آسان، به پایان رسیدن آن سریع و تفسیر آن آسان بود. با این حال، در سال های گذشته وضعیت تغییر کرده است و SVM و شبکه های عصبی حرف اول را می زنند.
ماشین بردار پشتیبان (Support Vector Machine)
برای طبقه بندی و رگرسیون می توان از ماشین بردار پشتیبان (SVM) استفاده کرد، اما این الگوریتم عمدتا در مشکلات طبقه بندی که نیاز به تقسیم یک مجموعه داده به دو کلاس توسط یک ابرپیما دارد، استفاده می شود. هدف این است که یک ابرپیما با بیشترین حاشیه ممکن یا فاصله بین ابرپیما و هر نقطه از مجموعه آموزش انتخاب کنید، به طوری که داده های جدید به درستی طبقه بندی شوند. بردارهای پشتیبانی نقاط داده ای هستند که نزدیکترین حد به ابرپیما هستند و در صورت حذف موقعیت آن را تغییر می دهند. در SVM، تعیین پارامترهای مدل یک مسئله بهینه سازی محدب است، بنابراین راه حل همیشه بهینه جهانی است.

SVM ها به طور گسترده در تحقیقات بالینی مورد استفاده قرار می گیرند، به عنوان مثال، برای شناسایی نشانگرهای زیستی تصویربرداری، تشخیص سرطان یا بیماری های عصبی، و به طور کلی برای طبقه بندی داده ها از مجموعه داده های نامتعادل یا مجموعه داده ها با مقادیر از دست رفته.
شبکه های عصبی
در شبکه های عصبی ، ارتباط بین نتیجه و متغیرهای ورودی از طریق ترکیب لایه های مخفی عملکردهای از پیش تعیین شده به تصویر کشیده می شود. هدف این است که وزنها را از طریق داده های ورودی و نتیجه ای تخمین بزنید به گونه ای که میانگین خطای بین نتیجه و پیش بینی آنها به حداقل برسد.

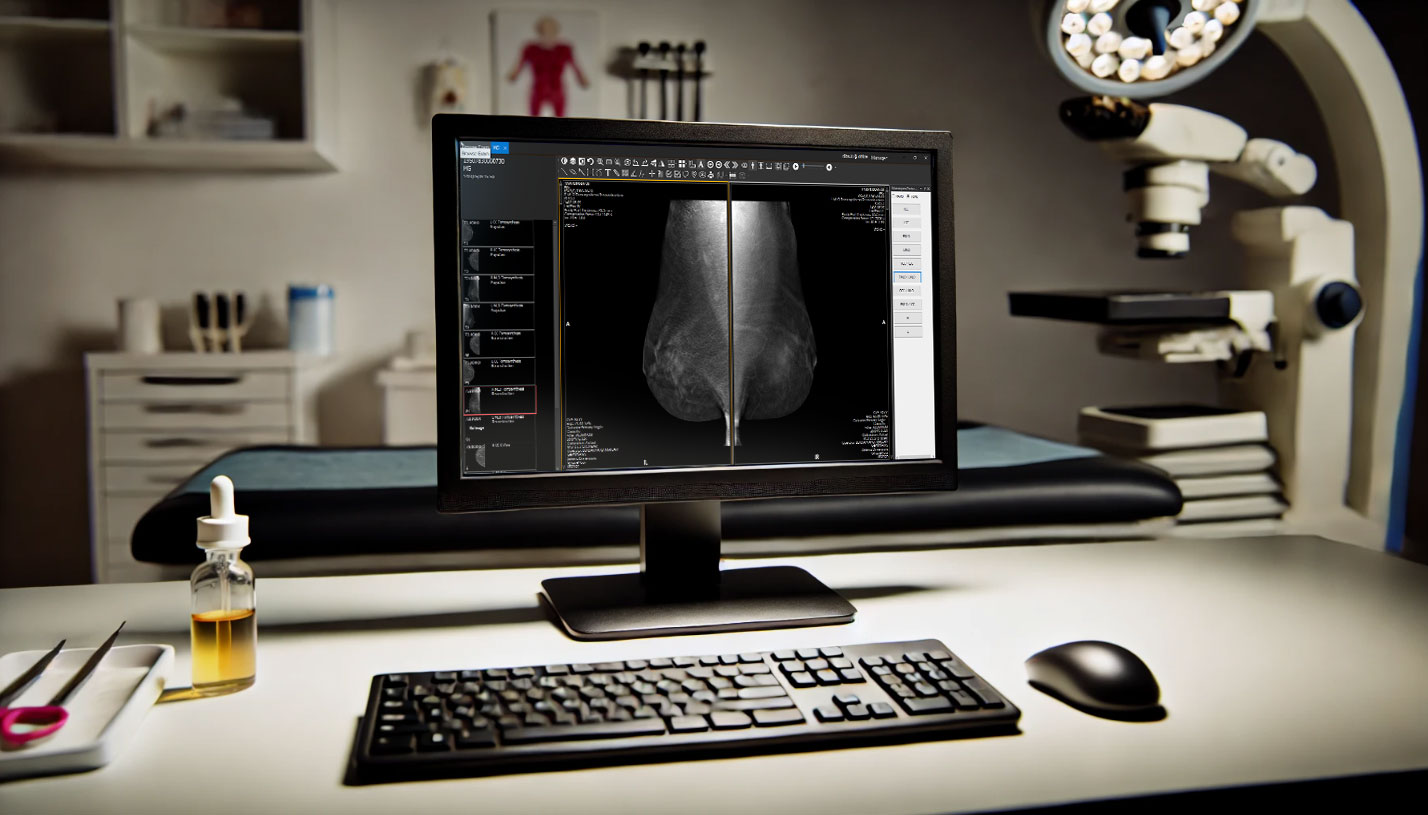
شبکه های عصبی با موفقیت در زمینه های مختلف پزشکی به کار گرفته شده اند؛ برای مثال سیستم های تشخیصی، تجزیه و تحلیل بیوشیمیایی، تجزیه و تحلیل تصویر و تولید دارو، همراه با نمونه هایی از پیش بینی سرطان پستان درکتاب درسی با استفاده از تصاویر ماموگرافی.
رگرسیون لجستیک
رگرسیون لجستیک یکی از الگوریتم های اساسی و همچنان محبوب برای مدل سازی نتایج دوقطبی است. از رگرسیون لجستیک برای بدست آوردن نسبت شانس درصورت وجود بیش از یک متغیر توضیحی استفاده می شود. رویه مشابه رگرسیون خطی چندگانه است، با این تفاوت که متغیر پاسخ دوجمله ای است. این تأثیر هر متغیر را بر نسبت شانس واقعه مشاهده شده مورد علاقه نشان می دهد. در مقابل رگرسیون خطی، با تجزیه و تحلیل ارتباط همه متغیرها با هم از اثرات مخدوش کننده جلوگیری می کند.

در مراقبت های بهداشتی، رگرسیون لجستیک به طور گسترده ای برای حل مشکلات طبقه بندی و پیش بینی احتمال یک رویداد خاص استفاده می شود، که آن را به ابزاری ارزشمند برای ارزیابی خطر بیماری و بهبود تصمیمات پزشکی تبدیل می کند.
پردازش زبان طبیعی
در مراقبت های بهداشتی، بخش عمده ای از اطلاعات بالینی به صورت متن روایی مانند معاینه بدنی، گزارش های آزمایشگاهی بالینی، یادداشت های عملیاتی و خلاصه هایی است که بدون برنامه های خاص پردازش متن، برای برنامه رایانه ای غیر ساختاری و قابل درک نیست. پردازش زبان طبیعی این موضوعات را برطرف می کند زیرا مجموعه ای از کلمات کلیدی مربوط به بیماری را در یادداشت های بالینی بر اساس پایگاه داده های تاریخی مشخص می کند که پس از اعتبار سنجی، داده های ساختاریافته را برای پشتیبانی از تصمیم گیری بالینی وارد و غنی می کند.
TF-IDF
الگوریتم اساسی برای استخراج کلمات کلیدی(TF-IDF) مخفف عبارت فرکانس معکوس فرکانسی-سند است. وزن TF-IDF واحد اندازه گیری آماری اهمیت کلمه برای یک سند در یک مجموعه یا مجموعه نوشته ها است. اهمیت، متناسب با تعداد دفعاتی که یک کلمه در سند ظاهر می شود، افزایش می یابد اما با فرکانس کلمه در مجموعه جبران می شود.

در مراقبت های بهداشتی، TF-IDF در یافتن شباهت بیماران در مطالعات مشاهده ای و همچنین در کشف همبستگی بیماری ها از گزارش های پزشکی و یافتن الگوهای پی در پی در پایگاه های داده مورد استفاده قرار می گیرد.
طبقه بندی Naïve Bayes
طبقه بندی Naïve Bayes یک روش اساسی برای دسته بندی متن، مسئله قضاوت اسناد به عنوان متعلق به یک دسته یا دسته دیگر است. طبقه بندی کننده Naive Bayes فرض می کند که وجود یک ویژگی خاص در یک کلاس با وجود ویژگی دیگر ارتباطی ندارد. حتی اگر این ویژگی ها به هم وابسته باشند، همه این خصوصیات به طور مستقل در احتمال تعلق به یک دسته خاص نقش دارند.

این یکی از موثرترین و کارآمدترین الگوریتم های طبقه بندی است و با موفقیت در بسیاری از مشکلات پزشکی مانند طبقه بندی گزارشات پزشکی و مقالات ژورنالی اعمال شده است.
بردارهای کلمه(Word Vectors)
به عنوان یک موفقیت در NLP، بردارهای کلمه، یا word2vec، یک گروه از مدل های مرتبط است که برای تولید تعبیه کلمات استفاده می شود. در اصل، مدل های word2vec شبکه های عصبی کم عمق و دو لایه ای هستند که زمینه های زبانی کلمات را بازسازی می کنند. Word2vec یک فضای برداری چند بعدی از متن تولید می کند و هر کلمه منحصر به فرد دارای یک بردار مربوطه است. بردارهای کلمه به گونه ای در فضای برداری قرار می گیرند که کلماتی که زمینه های مشترک دارند در نزدیکی یکدیگر قرار بگیرند.

بردارهای واژه برای پردازش زبان زیست پزشکی استفاده می شوند، از جمله یافتن شباهت، استاندارد سازی اصطلاحات پزشکی و کشف جنبه های جدید بیماری ها.
یادگیری عمیق
یادگیری عمیق امتداد تکنیک شبکه عصبی کلاسیک است، به عبارت ساده، به عنوان یک شبکه عصبی با لایه های مختلف تعریف می شود. با داشتن ظرفیت های بیشتر در مقایسه با الگوریتم های کلاسیک ML، یادگیری عمیق می تواند الگوهای غیر خطی پیچیده تری را در داده ها کشف کند. با توجه به اینکه خط لوله ماژول های قابل آموزش هستند، یادگیری عمیق یک روش مقیاس پذیر را نشان می دهد که، از جمله می تواند استخراج خودکار ویژگی را از داده های خام انجام دهد.
در کاربردهای پزشکی، الگوریتم های یادگیری عمیق با موفقیت هم وظایف یادگیری ماشین و هم پردازش زبان طبیعی را برطرف می کنند. الگوریتم های یادگیری عمیق که معمولاً استفاده می شود شامل شبکه عصبی کانولوشن (CNN) ، شبکه عصبی راجعه، شبکه باور عمیق و پرسپترون چند لایه است. که از سال ۲۰۱۶ به بعد CNN ها پیشتاز این عرصه بوده اند.
شبکه عصبی کانولوشن
CNN برای رسیدگی به داده های با ابعاد بالا یا داده هایی با تعداد زیادی صفات مانند تصاویر ساخته شده است. در ابتدا، همانطور که توسط LeCun پیشنهاد شد، ورودی های CNN مقادیر پیکسلی نرمال بر روی تصاویر بودند. شبکه های کانولوشنال از فرایندهای بیولوژیکی والگوی اتصال بین سلولهای عصبی شبیه سازمان قشر بینایی حیوانات الهام گرفته اند که با سلولهای عصبی قشر منحصر به فرد فقط در یک منطقه محدود از زمینه پذیرش به محرک پاسخ می دهند. با این حال، زمینه های پذیرای نورون های مختلف تا حدی با هم همپوشانی دارند به طوری که کل حوزه بینایی را پوشش می دهند. سپس CNN با توزین در لایه های کانولوشن و نمونه برداری در لایه های زیر نمونه، مقادیر پیکسل را در تصویر منتقل می کند. خروجی نهایی تابعی بازگشتی از مقادیر ورودی وزنی است.

اخیراً، CNN در زمینه پزشکی برای کمک به تشخیص بیماری ها، مانند سرطان پوست یا آب مروارید، با موفقیت به کار گرفته شده است.
شبکه عصبی راجعه
RNN با کسب رتبه دومین الگوریتم محبوب در مراقبت های بهداشتی، شبکه های عصبی است که از اطلاعات متوالی استفاده می کنند. RNN ها را راجعه می نامند زیرا برای هر عنصر از یک دنباله کار یکسانی را انجام می دهند و خروجی به محاسبات قبلی بستگی دارد. RNN ها دارای یک “حافظه” هستند که اطلاعات مربوط به آنچه را که چند گام به عقب محاسبه شده است، ضبط می کند. RNN با محبوبیت بالا در ، همچنین یک روش قدرتمند برای پیش بینی وقایع بالینی است.

تا همین اواخر، برنامه های کاربردی هوش مصنوعی در مراقبت های بهداشتی عمدتاً به چند نوع بیماری پرداخته بودند: سرطان ، بیماری سیستم عصبی و بیماری های قلبی عروقی که بزرگترین آنها هستند. در حال حاضر، پیشرفت در هوش مصنوعی و NLP و به ویژه توسعه الگوریتم های یادگیری عمیق، صنعت مراقبت های بهداشتی را به استفاده از روش های هوش مصنوعی در چندین حوزه از مدیریت تا کشف دارو سوق داده است.
منبع : medium.com