

در این مقاله، ما بر عملکرد ChatGPT در ترجمه گزارشهای رادیولوژی به نسخههای معمولی تمرکز میکنیم. همچنین، از ChatGPT میخواهیم بر اساس هر گزارش رادیولوژی، پیشنهاداتی را برای بیماران و ارائهدهندگان مراقبتهای بهداشتی ارائه کند و سپس کیفیت پیشنهادات ارائه شده را ارزیابی میکنیم.
شیوه گزارشگیری از عملکرد ChatGPT
برای نشان دادن عملکرد ChatGPT در مجموعهای از گزارشهای رادیولوژی منتخب، ما ۶۲ گزارش غربالگری CT قفسه سینه و ۷۶ گزارش غربالگری MRI مغز را از پایگاهداده بالینی Atrium Health Wake Forest Baptist جمعآوری کردیم. همه گزارشها بین ۱ و ۱۳ فوریه تولید شده است.
گزارشهای غربالگری CT قفسه سینه از پروتکل غربالگری سرطان ریه سیتی سیتی با دوز پایین بدون دخالت مواد حاجب انجام شدند. بیماران بین ۵۳ تا ۸۰ سال با میانگین سنی ۶۶.۹ سال (۳۲ مرد و ۳۰ زن) هستند. گزارش ها توسط ۱۱ رادیولوژیست مجرب با میانگین ۵۷ ± ۲۷۸ کلمه نهایی شد. گزارش ها بر اساس دسته کلی Lung-RADS نشان داده شده در هر گزارش به ۶ کلاس طبقه بندی شدند (۱، 1S، ۲، 2S، ۳، 4A).
گزارش های غربالگری MRI مغز از پروتکل تومور مغزی با و بدون استفاده از ماده حاجب انجام شدند. محدوده سنی بیمار بین ۵ تا ۹۸ سال با میانگین سنی ۵۵.۰ سال (۴۵ مرد و ۳۱ زن) است. گزارش ها توسط ۱۴ رادیولوژیست مجرب با ۹۲ ± ۲۴۷ کلمه نهایی شد. گزارشها بر اساس یافتههای مربوط به متاستازها به ۳ کلاس طبقهبندی شدند: عدم وجود متاستاز، وضعیت پایدار بدون متاستازهای جدید یا در حال رشد، و بدتر شدن وضعیت با متاستازهای در حال رشد یا تازه ظهور.
در آزمایشهای خود، سه دستور زیر را به ChatGPT دادیم و پاسخهای آن را ضبط کردیم:
- لطفاً گزارش رادیولوژی را به زبان ساده و قابل فهم ترجمه کنید.
- لطفاً چند پیشنهاد برای بیمار ارائه دهید.
- لطفاً چند پیشنهاد برای ارائه دهنده خدمات بهداشتی ارائه دهید. تمام پاسخ های ChatGPT در اواسط فوریه جمع آوری شد.
پس از جمع آوری تمام پاسخ های ChatGPT، ما از دو رادیولوژیست مجرب (با تجربه ۲۱ و ۸ ساله) دعوت کردیم تا کیفیت پاسخ های ChatGPT را ارزیابی کنند.
برای ترجمه گزارش، تلاش ارزیابی بر سه جنبه متمرکز بود: نمره کلی، کامل بودن و صحت (overall score, completeness, and correctness). رادیولوژیستها در هر یک از گزارش های ترجمه شده تعداد مکان هایی که اطلاعات از دست رفته و همچنین تعداد مکان های اطلاعات نادرست را ثبت کردند و بر اساس سیستم ۵ امتیازی (۱ برای بدترین و ۵ برای بهترین) نمره کلی دادند. سپس ما تجزیه و تحلیل آماری را بر روی بازخورد رادیولوژیست ها انجام دادیم. به عنوان مثال، اگر ده گزارش ترجمه شده وجود داشته باشد و رادیولوژیست ها یک مکان از اطلاعات را در میان آنها گم کرده باشند، به این نتیجه می رسیم که به طور متوسط ۰.۱ مکان اطلاعات گم شده است.
گزارشهای ترجمه شده با ChatGPT در مقایسه با گزارشهای اصلی
در مقایسه با گزارشهای رادیولوژی اصلی، ChatGPT نسخههایی به زبان ساده با کلمات کمتر در هر دو مورد سی تی قفسه سینه و MRI مغز تولید کرد. برای گزارشهای CT قفسه سینه، ۸۵.۵ درصد نتایج ترجمه (۵۳ از ۶۲) کوتاهتر از گزارشهای اصلی مربوطه با کاهش طول کلی ۲۶.۷ درصد است. به طور خاص، ChatGPT می تواند طول گزارش های اصلی را به ترتیب ۲۰.۵٪، ۲۹.۰٪، ۲۹.۰٪، ۵۴٪ و ۲۹.۴٪ برای Lung-RADS دسته ۱، ۲، 2S، ۳ و 4A کاهش دهد. تنها استثنا دسته 1S با افزایش طول ۱۳.۳٪ پس از ترجمه ChatGPT است. برای گزارش های رادیولوژی MRI مغز، ۷۲.۴٪ از نتایج ترجمه (۵۵ از ۷۶) دارای کلمات کمتری نسبت به گزارش های اصلی متناظر با کاهش طول کلی ۲۱.۱٪ هستند. به جز دسته «no mats» با کلمات کمی (۱.۸%)، گزارشها در همه دستههای دیگر پس از ترجمه ChatGPT کوتاهتر هستند. به طور خاص، نسخههای زبان ساده گزارشها در دستههای «پایدار» و «وخیمتر» به ترتیب ۱۳.۱ درصد و ۳۴.۱ درصد کوتاهتر از نسخههای اصلی هستند.
یک سناریوی معمولی کوتاه کردن پاراگراف زمانی اتفاق میافتد که مکانهای متعددی در گزارش رادیولوژی وجود داشته باشد که هیچ ناهنجاری را نشان نمیدهد. سپس ChatGPT همه آن یافته های منفی را در یک جمله خلاصه کرد. به عنوان مثال، در یک گزارش سی تی قفسه سینه، نوشته شده بود: “PLEURA: بدون ضخیم شدن یا افیوژن پلور. بدون پنوموتوراکس. قلب: اندازه قلب طبیعی است. بدون افیوژن پریکارد. کلسیفیکاسیون عروق کرونر: وجود ندارد. مدیاستینوم/هیلوم/آگزیلا: وجود ندارد.” ChatGPT متن را به این صورت ترجمه کرد: پلورا، قلب و عروق خونی طبیعی هستند و هیچ نشانه ای از سرطان در غدد لنفاوی وجود ندارد.
جدا از کوتاه کردن پاراگراف ها و تقطیر اطلاعات، گزارش های ترجمه شده با جایگزین کردن اصطلاحات پزشکی با کلمات رایج، برای بیمار مناسب بوده و درک آن آسان تر است. به عنوان مثال، در یک گزارش سی تی قفسه سینه در مورد یافته های ریه آمده است: “گرانولوم در لوب میانی راست ۱ میلی متر دیده می شود.” ChatGPT متن را به این جمله ترجمه کرده است: “یک ناحیه کوچک ۱ میلی متری در لوب میانی سمت راست وجود دارد که شبیه گرانولوم است، که ناحیه کوچکی از التهاب است که معمولا نگران کننده نیست.” پس از ترجمه ChatGPT، اصطلاحات پزشکی گرانولوما با شدت آن نیز توضیح داده شد.
یکی دیگر از ویژگی های مهم گزارش ترجمه شده یکپارچه سازی اطلاعات است. ChatGPT قادر است اطلاعات نشان داده شده در بخش های مختلف گزارش اصلی را یکپارچه کند تا بیمار بتواند گزارش را بهتر درک کند. یک مثال خوب گزارش سی تی قفسه سینه است. این گزارش با اسکن انجام شده در ۶ آگوست ۲۰۲۱ در بخش مقایسه مقایسه شده است. در بخش یافته ها جمله ای وجود دارد که گرانولوم لوب پایین سمت راست ۶ میلی متر بدون تغییر وجود دارد. ChatGPT اطلاعاتی را که در بخش مقایسه و یافته ها نشان داده شده است یکپارچه کرد و جمله زیر را ایجاد کرد: “همچنین یک
granuloma گرانولوم ۶ میلی متری در لوب پایین سمت راست، اما از سی تی اسکن قبلی انجام شده در آگوست ۲۰۲۱ تغییری نکرده است.
ارزیابی ترجمه های ChatGPT توسط رادیولوژیستها
ما از دو رادیولوژیست برای ارزیابی کیفیت گزارشهای ترجمه شده دعوت کردیم. ارزیابی بر اساس سه معیار بود: تعداد مکانهای با اطلاعات از دست رفته، تعداد مکانهایی که اطلاعات اشتباه تفسیر شده و امتیاز کلی. امتیاز کلی بر اساس سیستم ۵ امتیازی داده شد که در آن نمره ۵ نشان دهنده بهترین کیفیت و نمره ۱ به معنای بدترین کیفیت است.
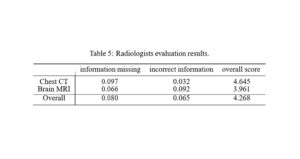
جدول ۵ آماری که تصویر آن در زیر امده است، از نتایج ارزیابی رادیولوژیست ها را فهرست می کند. می توان دریافت که ChatGPT در هر دو گزارش CT قفسه سینه و اسکن MRI مغز عملکرد خوبی داشته است. تنها ۰.۰۹۷ مکان اطلاعات گم شده و ۰.۰۳۲ مکان اطلاعات نادرست به طور متوسط در هر گزارش CT قفسه سینه وجود دارد، که به معنی یک بار در هر ۱۰.۳ گزارش ترجمه و یک بار در هر ۳۱.۳ گزارش ترجمه شده است. در میان تمام گزارشهای سیتی سیسینه ترجمهشده، ۷۶ درصد نتایج با نمره کلی ۵ رتبهبندی میشوند. در مورد ترجمههای گزارش اسکن MRI مغز، ۵ درصد نتایج نشان میدهند که اطلاعات گم شده است، و بهطور متوسط ۰.۰۶۶ مکان اطلاعات از دست رفته در هر گزارش وجود دارد. این در حالی است که ۹ درصد از گزارش های ترجمه شده با اطلاعات نادرست است و به طور متوسط ۰.۰۹۲ محل نادرستی در هر گزارش وجود دارد. ۳۷٪ و ۳۲٪ از کل نتایج اسکن MRI مغز به ترتیب با نمره کلی ۴ و ۵ رتبه بندی می شوند. به طور کلی، میانگین تعداد اطلاعات مفقود و نادرست برای همه نتایج به ترتیب ۰.۰۸۰ و ۰.۰۶۵ است، با فراوانی تقریباً یک بار در هر ۱۲.۵ و ۱۵.۴ گزارش. میانگین امتیاز کلی همه نتایج ۴.۲۶۸ است که در آن ۲۷ درصد و ۵۲ درصد از کل نتایج به ترتیب با نمره کلی ۴ و ۵ رتبه بندی شده اند.
ارزیابی پیشنهادات ایجاد شده توسط ChatGPT
ChatGPT هنگام ارائه پیشنهادات برای بیماران و ارائه دهندگان مراقبت های بهداشتی ادعا کرد که در حال حاضر نمی توانند مشاوره پزشکی یا درمان ارائه دهند. با این حال، پیشنهادات کلی را برای بیماران یا ارائه دهندگان مراقبت های بهداشتی ارائه می دهد. برای حدود ۳۷ درصد از همه موارد، ChatGPT بر اساس یافتههای گزارش رادیولوژی پیشنهادات خاصی ارائه کرد.
صحت ترجمههای ChatGPT
مشخص شد که ترجمه ChatGPT برای هیچ گزارش رادیولوژی خاص، با طولهای مختلف پاراگرافهای سازماندهیشده و انتخابهای انعطافپذیر از کلمات جایگزین، منحصربهفرد نیست. از این رو، بررسی تصادفی بودن پاسخهای ChatGPT ضروری است. ما ۱۰ ترجمه را از همان گزارش رادیولوژی CT قفسه سینه جمع آوری کردیم و هر گزارش ترجمه شده را بررسی کردیم. ما ابتدا گزارش رادیولوژی اصلی را به ۲۵ نقطه اطلاعات کلیدی تقسیم کردیم و سپس صحت و کامل بودن هر نقطه مربوطه را در هر گزارش ترجمه شده به صورت نقطه به نقطه ارزیابی کردیم. نتایج ما در مورد گزارش های رادیولوژی CT قفسه سینه در جدول ۸ نشان داده شده است، جایی که “خوب” به این معنی است که اطلاعات به وضوح ترجمه شده است، “مفقود” نشان می دهد که نقطه اطلاعات به طور کامل در ترجمه از بین رفته است، “نادرست” نشان دهنده تنها اطلاعات جزئی است که در ترجمه نگهداری می شود. گزارش ترجمه شده، و “نادرست” تفسیر نادرست ChatGPT از گزارش اصلی رادیولوژی را نشان می دهد. به طور کلی ترجمه خوب ۵۵.۲٪ از کل نکات ترجمه شده را به خود اختصاص می دهد و به ترتیب ۱۹.۲٪، ۲۴.۸٪ و ۰.۸٪ نکات اطلاعاتی کاملا حذف شده، تا حدی ترجمه شده و تفسیر نادرست است. قابل ذکر است، برای ترجمه یافتههای ندول ریه، هر ۱۰ ترجمه فقط وضعیت پایدار ندولهای موجود را در مقایسه با غربالگری قبلی ذکر کردند و اطلاعات دقیقی مانند موقعیت دقیق هر ندول و اندازه هر ندول را ارائه نکردند. در نتیجه، ما در نظر می گیریم که تمام یافته های ندول ریه به اشتباه ترجمه شده اند. وقتی در گزارش اصلی به «هیچ گره جدیدی» اشاره شد، تنها یک ترجمه آن نکته را منعکس میکرد و ۹ ترجمه دیگر فقط به وضعیت پایدار ندولهای موجود اشاره کردند و این بیانیه که هیچ گره جدیدی در این غربالگری وجود ندارد را حذف کردند. تنها دو اطلاعات نادرست هر دو در ترجمه سابقه سیگار کشیدن بیمار اتفاق افتاد. ChatGPT به اشتباه ۳۰ pk-yr (30 بسته در سال – ۳۰ packs a year) را به ۳۰ سال ترجمه کرد. ChatGPT گاهی اوقات مشکلات جزئی ذکر شده در گزارش اصلی را نادیده می گیرد.
یافته ریوی “آمفیزم خفیف با ضخیم شدن جزئی دیواره برونش مرکزی به صورت دوطرفه” تنها به آمفیزم خفیف در اکثر ترجمه ها ترجمه شد و یافته جزئی دیگر آئورت قفسه سینه با کالیبر طبیعی با تغییرات آترواسکلروتیک جزئی در نه ترجمه از ده ترجمه نادیده گرفته شد.
قسمت اول این مقاله را در اینجا بررسی کنید.